长上下文推理时,模型需要保存历史 token 的 Key/Value。
这样生成下一个 token 会更快,但 cache 大小随上下文长度线性增长,显存和吞吐都会被拖住。
历史上下文
→
重要性打分
→
Top-K 保留
HubKV 的切入点:不重写 cache 系统,不重新训练 scorer,而是在 Top-K 之前修正分数。
长上下文推理时,模型需要保存历史 token 的 Key/Value。
这样生成下一个 token 会更快,但 cache 大小随上下文长度线性增长,显存和吞吐都会被拖住。
历史上下文
→
重要性打分
→
Top-K 保留
HubKV 的切入点:不重写 cache 系统,不重新训练 scorer,而是在 Top-K 之前修正分数。
F(S) = Σ si
每个 token 的价值固定,和已经选了什么无关。
问题:如果一片局部区域全都高分,Top-K 会连续保留很多相似 token。
F(S) = Σ max wi,j
新增收益取决于当前集合;附近已有代表 token 时,邻居的边际收益下降。
直觉:好的 cache 像摘要,要覆盖更多信息区域,而不是重复同一段。
HubKV 的论文主张:KV cache retention 应该从“捡最高分 token”转向“保留高分且覆盖互补的代表 token”。
Theory Lens
t1
t2
t3
hub
t5
t6
t7
t8
hub
t10
已经保留
它覆盖自己,也覆盖附近相似信息。
边际收益
同一局部区域已经被覆盖后,再保留邻居的增量应该打折。
预算流向
紧预算下,把 cache 从重复区域推向更广覆盖。
一句话:HubKV 不否认高分邻居重要,只是认为它们在 hub 已经存在时不应该继续按原始分数参与 Top-K 竞争。
hub 覆盖
neighbor 覆盖
overlap ρ
重叠越大,neighbor 能新增覆盖的面积越小。
理想目标
F(S) = ∑x maxj∈S wx,j
真实局部边际收益
Δ(i | {h}) = (1 − ρ(i,h)) si
SMD 的并行近似
s̃i = γ si
当局部 overlap ρ ≈ 1 − γ 时,SMD 的折扣分数 γsᵢ 就是在近似真实 marginal gain。
局部唯一峰值保持原分,邻居乘 γ,所以 hub 一定排在邻居前面。
sh > si ⇒ sh > γsi
如果局部覆盖重叠接近 1−γ,SMD 分数就在真实边际收益附近。
|Δ(i|{h}) − γsi| ≤ ηsi
ratio gate 和 clipped head weight 限制改动幅度,不会任意推翻 base scorer。
zi = (1−λ)si + λui
HubKV 是一个局部 submodular marginal-gain proxy。
HubKV 继承了 greedy submodular maximization 的全局 1−1/e 保证。
Observation
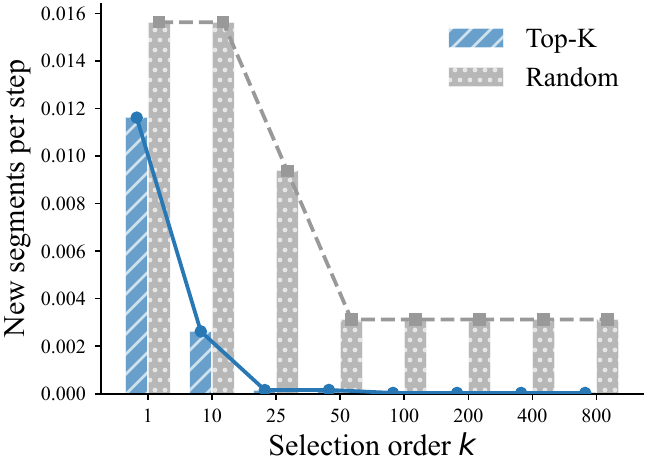
Top-K 很快开始重复覆盖同一局部区域。
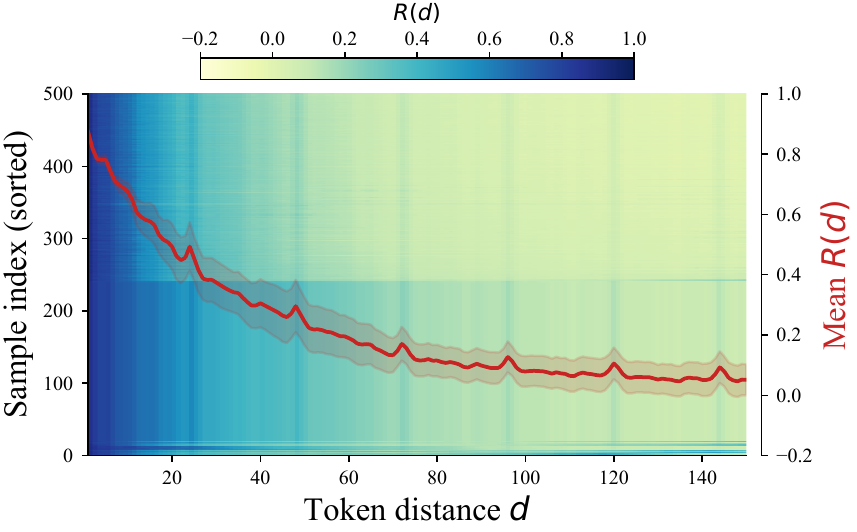
高分 token 往往成簇出现,不是孤立点。
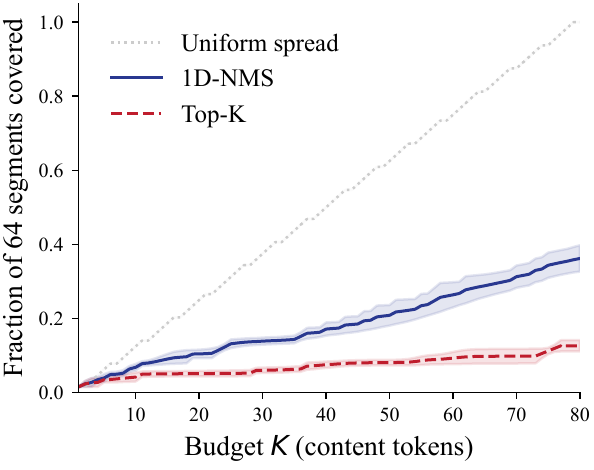
局部抑制可以把预算推向更多 segment。
Figures from the current HubKV paper draft: empirical motivation panels.
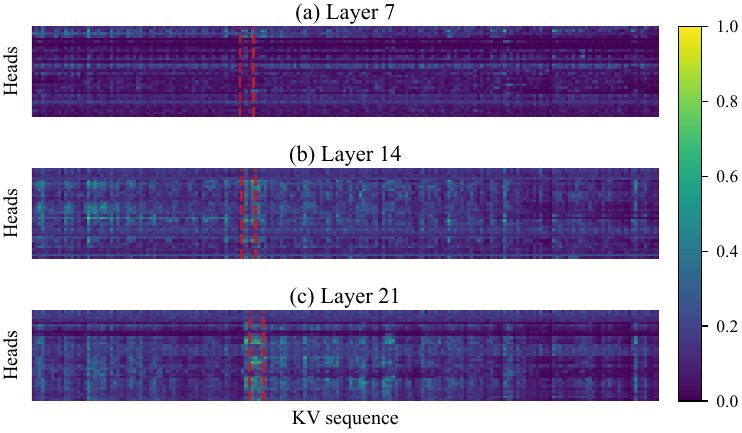
尖锐 head 像定位器,分数集中在少量 token。
平坦 head 像背景信号,对很多 token 给相似分数。
方法启发:不能只做 token-level NMS,还要做 bounded head-wise calibration。
一个 hub 覆盖邻近信息
另一个 hub 覆盖新区域
Submodular greedy 会逐步选择边际收益最大的 token,但它是顺序过程,推理时太贵。
用一维局部 hub detection + neighbor discount 做 first-order proxy,保持并行 Top-K 接口。
Method

Base scorer 负责产生分数;HubKV 只在排序前做局部冗余修正;最后仍交给 Top-K-style pruning。
1
用 kernel width 5 的 max-pooling 找局部峰值。
2
hub 保持原分;non-hub 邻居乘以 0.5。
3
按 selectivity 做温和权重,限制在 [0.8, 1.2]。
4
用 α = compression_ratio² 控制修正强度。
zᵢ = sᵢ + r² · (βₕ · qᵢ − sᵢ)
Avg-pool 平滑效果一般,可能因为它让高分区域更厚,和去冗余目标相反。
CommunitySmooth
SVD、IB、固定 head weight 效果一般,可能因为它们会抹掉关键 anchor。
SVD / IB / Head NMS
随机贪心更接近理论 oracle,但运行路径更重,整体收益不如当前方案。
Stochastic Greedy
最终方案之所以保留,是因为它目前效果最好;机制上,它保留 NMS 的有效内核,并用 mild calibration 与 ratio gate 控制扰动。
1. Bottleneck
KV cache 太大,必须删。
2. Flaw
Top-K 把 token utility 当成独立。
3. Evidence
高分 token 局部成簇,head 选择性不同。
4. Model
用 submodular local coverage 表达 diminishing returns。
5. Method
SMD + head calibration + ratio gate。
6. Claim
不是全局优化器,而是可并行的 marginal-gain proxy。
最终选择当前方案,直接原因是实验效果最好;理论部分提供的是理解它为何合理的解释框架。